Wals Roberta Sets 1-36.zip Work Review
Flocus is a free browser-based dashboard
to fuel your productivity, all in one place.

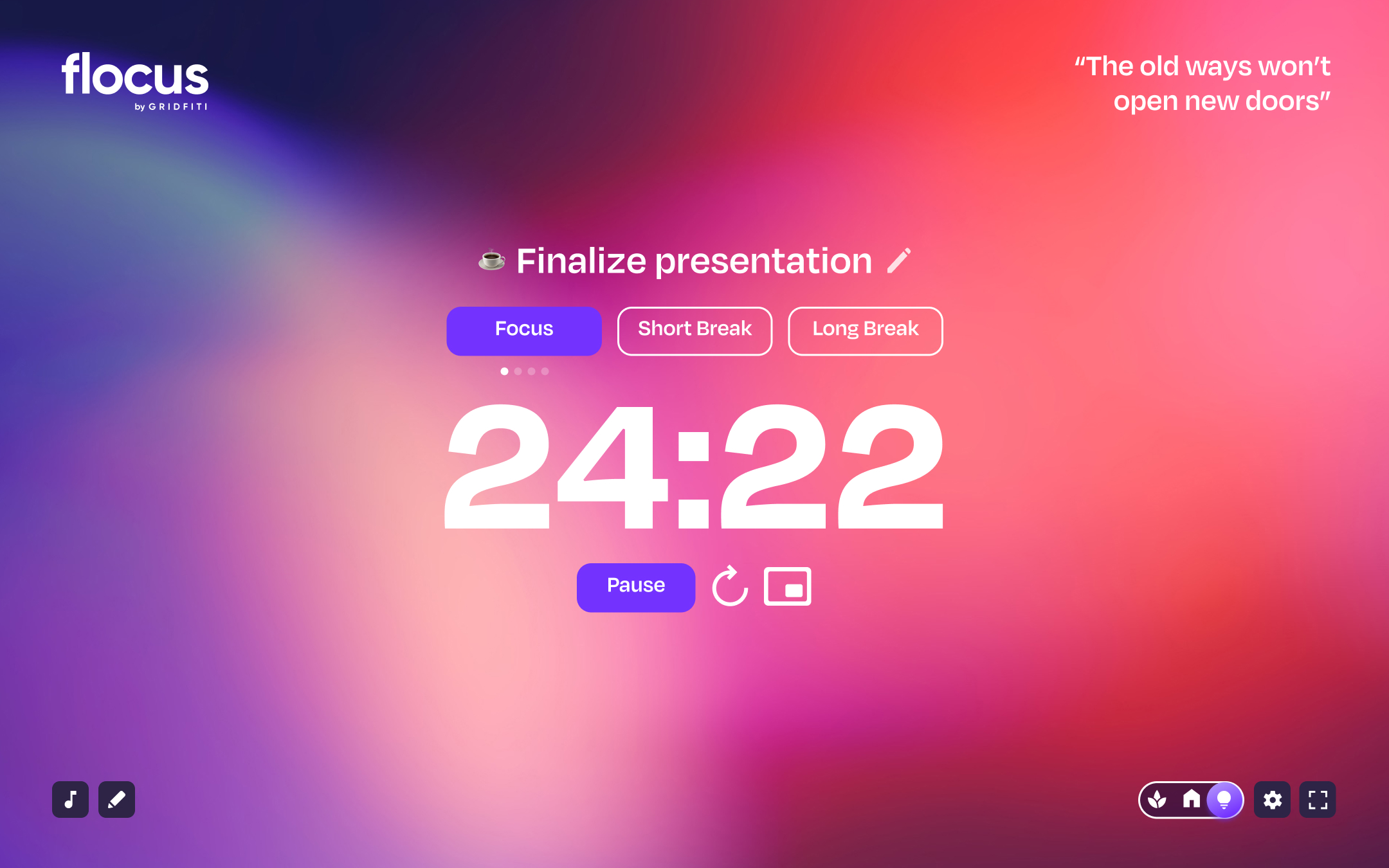
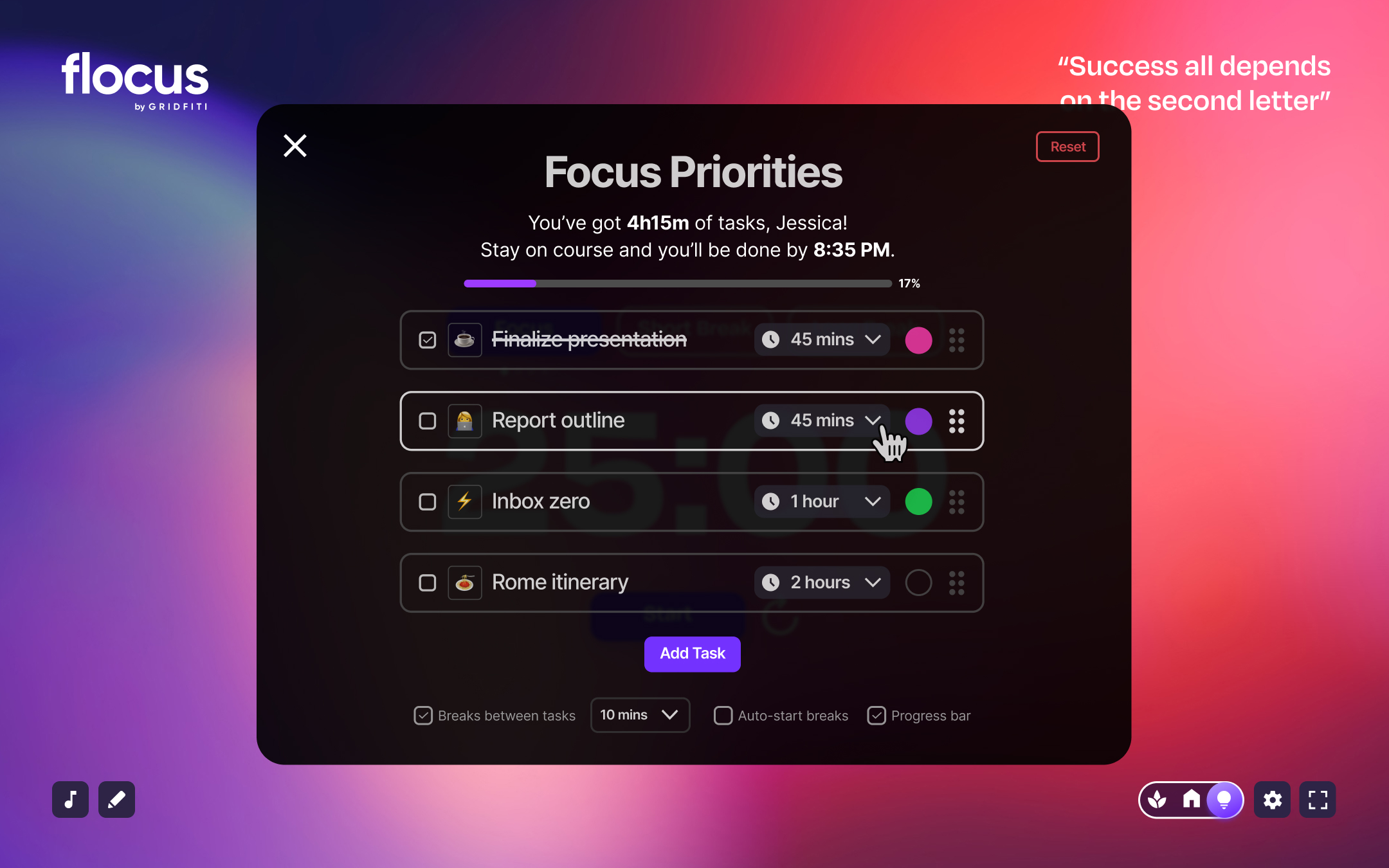
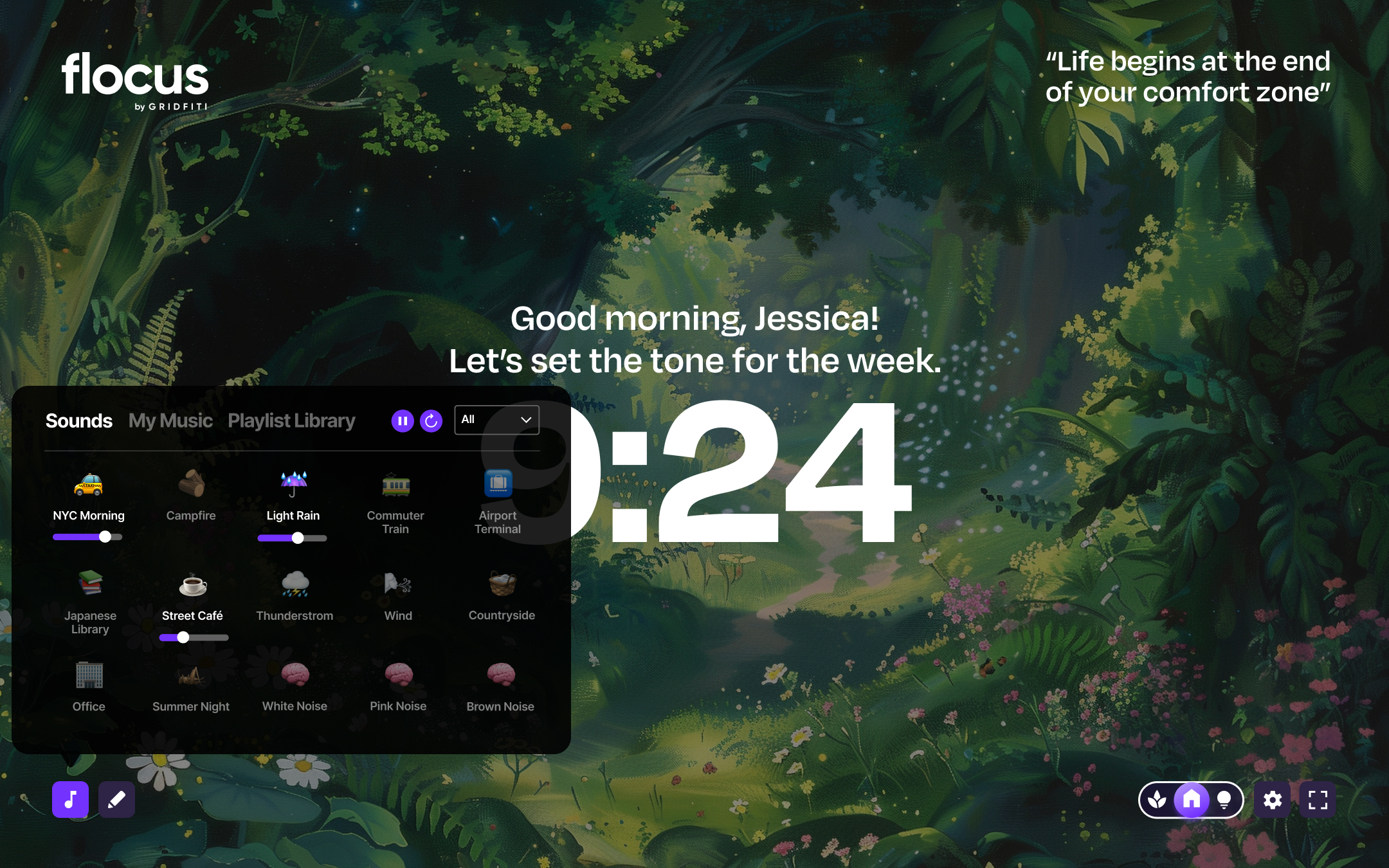
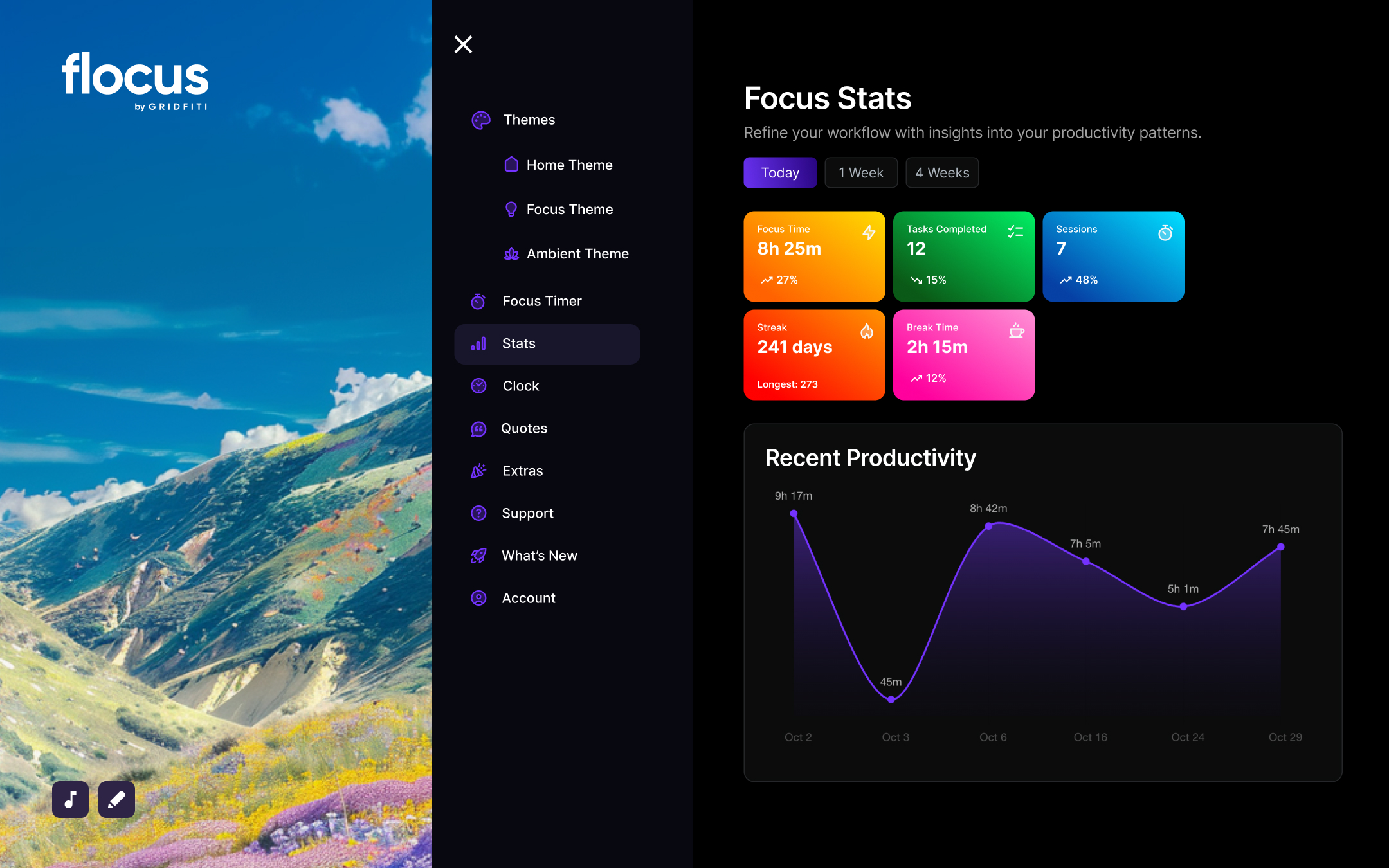

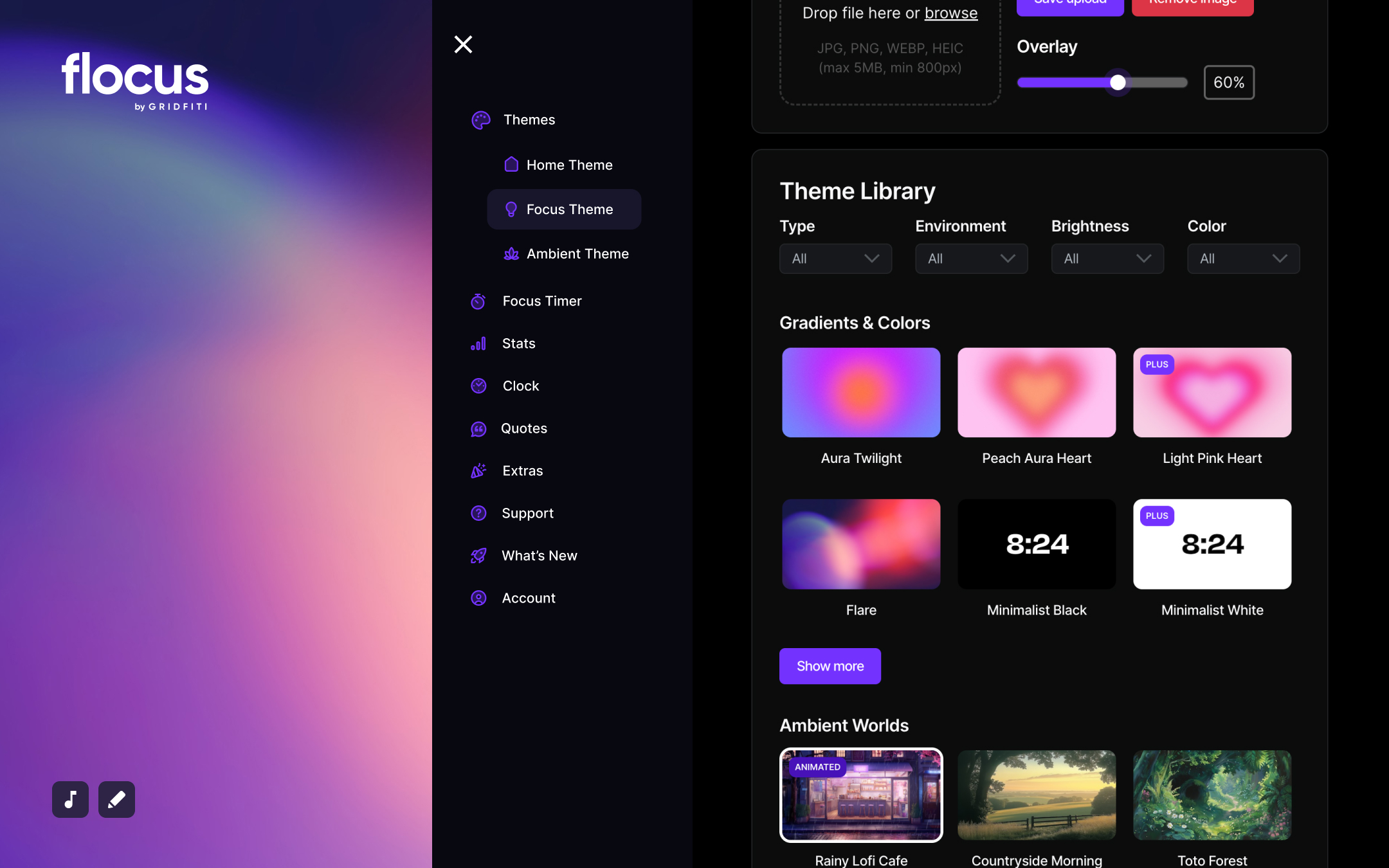
Flocus is a free browser-based dashboard
to fuel your productivity, all in one place.
Loved and trusted by over 1 million humans at top schools and companies

We’re here to redefine the way you work and recharge every day, without overcomplicating it.
Whether you’re a professional, student, or go-getter, Flocus is here to make your productivity journey more efficient, personalized, and beautiful.
Go to Flocus in browserSeamlessly toggle between your personal home base, focus sessions, and soothing breaks.
Try it for yourself:


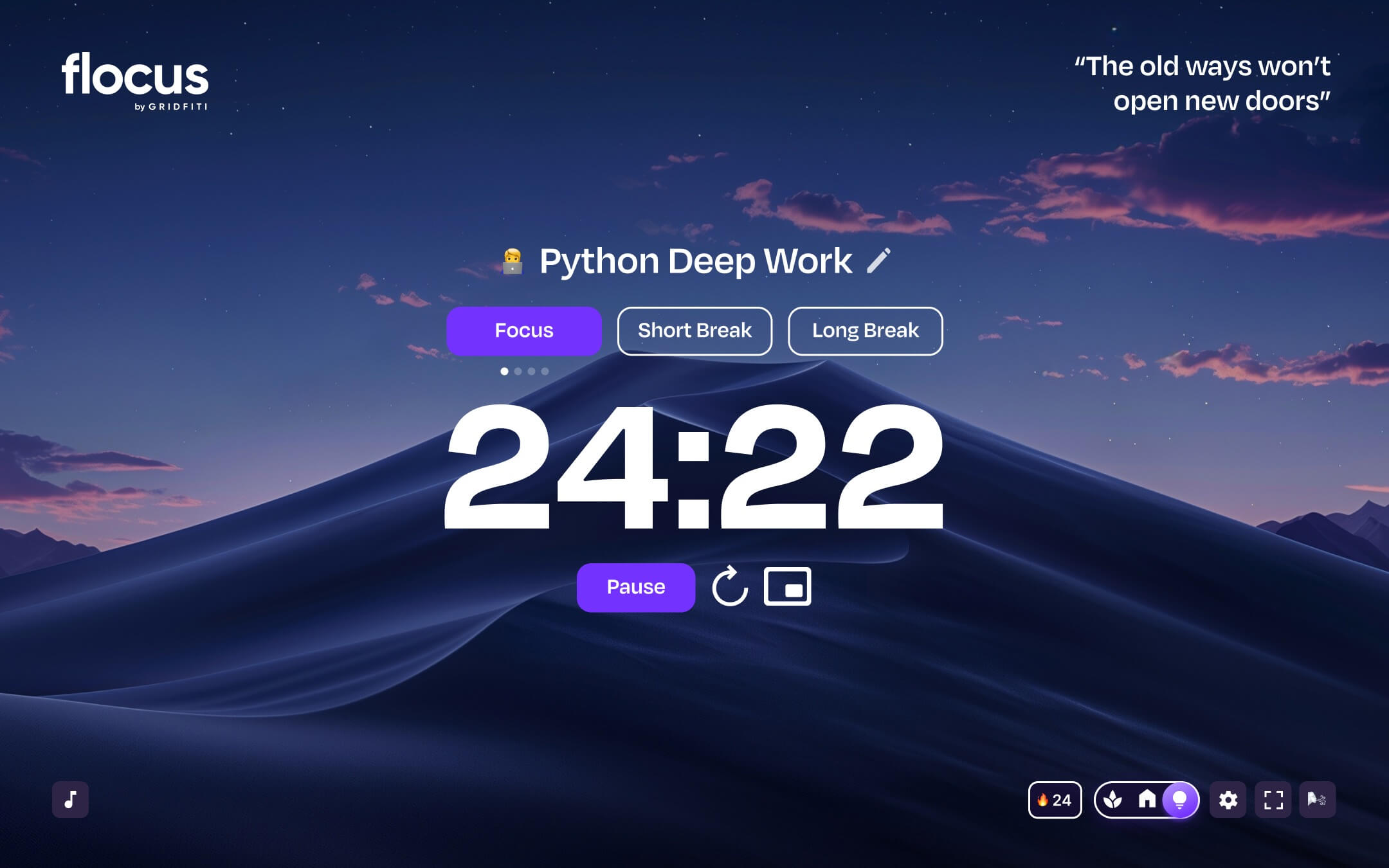
Whether you’re on your grind or ready to unwind — your dash is there for every part of your day.
Go to FlocusThis ZIP file likely refers to the World Atlas of Language Structures (WALS) data, specifically curated or formatted for use with (Robustly Optimized BERT Pretraining Approach).
Here is an overview of how these two components intersect in modern computational linguistics.
The Bridge Between Typology and Transformers: WALS and RoBERTa
The field of Natural Language Processing (NLP) has shifted from rule-based systems to massive neural networks like RoBERTa. While these models are incredibly powerful, they are often "linguistically agnostic," meaning they learn patterns from raw text without an inherent understanding of grammar. The WALS Roberta Sets represent an effort to ground these models in linguistic typology 1. Understanding the Components WALS (World Atlas of Language Structures):
This is a preeminent database of structural properties of languages (phonological, grammatical, lexical) gathered from descriptive materials. It categorizes languages by "features"—such as word order (Subject-Object-Verb), the presence of specific phonemes, or grammatical gender.
Developed by Meta AI, RoBERTa is a transformer-based model that improved upon BERT by training on more data with larger batches and removing the "next sentence prediction" objective. It is the engine used to create "embeddings" or mathematical representations of language. 2. The Purpose of the "Sets" The "Sets 1-36" likely refer to partitioned data used for Fine-tuning
Researchers use WALS data to see if RoBERTa "knows" linguistics. For example, if we feed the model sentences from a language it hasn't seen much of, can its internal vectors predict that language's word order (Feature 81A in WALS)? Cross-Lingual Transfer:
By aligning RoBERTa with WALS features, developers can help the model perform better on "low-resource" languages. If the model knows that Language A and Language B share 90% of their WALS features, it can transfer knowledge from one to the other more effectively. 3. Why This Matters Most AI models suffer from English-centric bias . Integrating WALS data allows researchers to: Quantify Linguistic Diversity:
It moves AI beyond just "translating" and toward "understanding" the structural diversity of the world's 7,000+ languages. Improve Model Robustness: A model that understands the WALS Roberta Sets 1-36.zip
of a language (via WALS) is less likely to make "hallucination" errors when dealing with complex syntax. Conclusion WALS Roberta Sets 1-36
The file "WALS Roberta Sets 1-36.zip" is an archive containing 36 sets of pre-trained models designed for linguistic and machine learning research. These sets typically represent unique combinations of language data, model sizes, and specific configurations used to analyze structural properties of human languages. Key Components and Context
WALS (World Atlas of Language Structures): This refers to a massive online database of structural properties (phonological, grammatical, lexical) for over 2,600 languages. It is a primary resource for linguists to compare cross-linguistic diversity.
RoBERTa (Robustly Optimized BERT approach): A popular transformer-based model developed by Meta AI. It is widely used for Natural Language Processing (NLP) tasks such as text classification, question answering, and semantic search.
Sets 1-36: These represent 36 distinct variations or training stages. Researchers often use these sets to compare how model performance or linguistic understanding evolves across different data samples or language families. Applications in Research
This specific zip file is often associated with computational linguistics projects that aim to bridge the gap between deep learning models and theoretical linguistic data. Common uses include:
Cross-Linguistic Benchmarking: Testing if AI models like RoBERTa can learn the structural rules documented in the WALS dataset.
Model Efficiency: Comparing performance across 36 different model variants to find the optimal balance between size and accuracy. This ZIP file likely refers to the World
Data Portability: Distributing pre-trained weights in a single archive allows researchers to load models quickly in environments like Kaggle or Google Colab without needing to re-train from scratch.
Note: Be cautious when downloading .zip files from unfamiliar third-party sources, as they can sometimes be used as masks for unwanted software or unrelated content in forum-style sites. Cutting-edge kitchen knives - Scripps Ranch News
The file "WALS Roberta Sets 1-36.zip" refers to a specific dataset associated with the WALS (World Atlas of Language Structures) and the RoBERTa (Robustly Optimized BERT Pretraining Approach) language model.
This file is typically used by researchers and developers working in computational linguistics and Natural Language Processing (NLP). It generally contains pre-processed linguistic feature sets designed to help AI models understand structural variations across different world languages [1, 2]. Understanding the Components
To understand what this zip file contains, it helps to break down its two main elements:
WALS (World Atlas of Language Structures): This is a large database of structural (phonological, grammatical, lexical) properties of languages gathered from descriptive materials. It categorizes languages by features like word order, number of genders, or vowel patterns [1, 3].
RoBERTa: This is a highly popular transformer-based model developed by Meta AI. It is an "optimized" version of Google’s BERT, trained on more data for a longer duration to better predict masked words in a sentence [2, 4]. Why are these "Sets" used together?
The "Sets 1-36" likely represent specific benchmarks or fine-tuning data. Researchers often map WALS linguistic features onto RoBERTa's embeddings to: Verify archive integrity:
Improve Cross-Lingual Transfer: Helping a model trained in English perform better in "low-resource" languages (languages with less digital data) [2, 5].
Analyze Probing Tasks: Testing if a model like RoBERTa "knows" the grammar of a language by seeing if its internal representations correlate with the documented features in WALS [4, 6].
Typological Prediction: Using AI to predict missing information in the WALS database for under-studied languages [3, 5]. How to Use the Dataset
If you have downloaded this specific zip file for a project, it usually includes CSV or JSON files organized into 36 distinct categories or "sets." These are often formatted for use in Python environments, specifically with libraries like transformers, scikit-learn, or PyTorch [2, 6].
Safety Note: Always ensure you are downloading datasets from reputable academic repositories like Hugging Face, GitHub, or official University archives to avoid malware associated with obscure .zip filenames.
Given the specificity of your query, I'll outline a general approach to how one might create or look for such a resource, assuming you're interested in language models or datasets related to the WALS and possibly fine-tuned with Roberta models.
"WALS Roberta Sets 1–36.zip" appears to be a bundled collection of the Roberta-format datasets derived from the World Atlas of Language Structures (WALS) or a related resource formatted for training/evaluation with the RoBERTa family of language models. This monograph explains what these sets likely contain, how they can be used, practical steps to inspect and process them, recommended workflows for analysis or modeling, and guidance on licensing, reproducibility, and citation.
In the intersection of computational linguistics and typological databases, few resources are as intriguing—and as specifically named—as the file WALS Roberta Sets 1-36.zip. If you have stumbled upon this archive while preparing a multilingual model, a low-resource NLP task, or a linguistic research project, you have likely realized that standard documentation is sparse. This article serves as the definitive breakdown of what this file contains, how it was generated, and—most importantly—how to extract maximum value from its 36 structured sets.
The data is pre-processed to align with the input requirements of the RoBERTa model.
Balanced productivity right to your inbox
Sign up for our weekly newsletter, The Flow, for concise, value-packed focus and recharge tips.

© Gridfiti Inc. All rights reserved.
© Deep Leading Pulse 2026. All Rights Reserved.